Health Monitor Troubleshooting
Overview
This article covers advanced troubleshooting for health monitors. For general monitor definitions refer to the following links:
- Overview of Health Monitors
- Reasons a Server Can Be Marked Down
- Servers Flap Up / Down
- Manually Validate Server Health
General Health Monitor Trivia
- Multi-Pool — A server that exists in multiple pools will receive health checks for each pool it has membership within. An exception is if the pools are on the same Service Engine and configured with the same health monitor, in which case the redundant monitoring is not performed.
- Disabled — Health checks are not performed for disabled servers, servers within a pool that is not assigned to a VS, or a attached to a disabled virtual service.
- Scaled SEs — When scaling out a virtual service across multiple Service Engines, servers will receive active health checks from each SE for the VS. If one SE marks a server as up it will be included in the load balancing. If a second SE is unable to access the server, it will mark it down and not send traffic to that server. From the Controller UI, the server health icon may flip intermittently between red and green (or other color). The status flipping is due to the frequency when SEs report their status to the Controller.
- SNAT IP — If a SNAT IP is configured for a virtual service (refer to , the active SE will send monitors from the SNAT IP address. If a SNAT IP is not configured (which is the norm), the active SE initiates monitors from its interface IP. The standby SE will always send monitors from its interface IP.
- Standby SE — By default, the standby SE will send health checks. This behavior may be changed from the CLI for the SE Group of the SE.
- Send Interval — By default Avi Vantage sends checks based on the frequency defined by a monitor’s Send Interval timer. However, when a new health monitor or a new server is added to a pool, or when there’s a positive monitor response is received after a server has been marked down for a long time, Avi Vantage will quickly send additional checks. For example, if a new server is added to a pool with a monitor set to query every 20 seconds, and requires 3 consecutive positive responses, the server may not be marked up for nearly one minute. In this example, when the new server is added to the pool, Avi Vantage will send the first 3 checks as quickly as the server will respond back, potentially marking the server up within one or two seconds. Subsequent checks will be performed at the interval specified by the Send Interval setting of the health monitor.
- Port Translation Enabled — In this, the default and most typical case,
- The server ports a virtual service targets will necessarily have been defined.
- If active monitoring is desired, but no monitor ports are explicitly defined, Avi Vantage can and will infer them from the defined server ports (on a per-server basis).
- Port Translation Disabled — On the other hand, if port translation is disabled, then:
- Avi Vantage makes no assumptions on which server ports should be actively monitored.
- Therefore, in this case, if active health monitoring is desired, one must add a health monitor for each port on the servers needing to be monitored.
Verifying Monitor Results
Verifying the results of health monitors is not always straightforward. Avi Vantage does not include health monitors when recording logs for client traffic for a virtual service. Below are a number of methods for inspecting the results received by active health monitors.
Via GUI
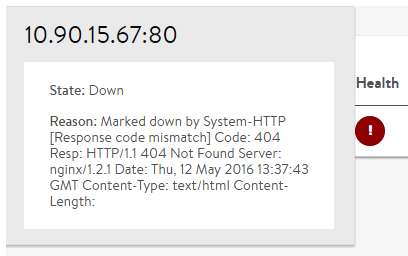
From the GUI, there are multiple ways to check the status of a server or see why it has been marked down:
- Mouse over a down (red) server icon.
- From the pool > server page, click the failed monitor in the health monitor table to expand the results.
- Events for the virtual server and pool record up / down status changes and reasons.
- More examples are available in the Reasons a Server Can Be Marked Down.
Via CLI and API
From the CLI and API, extensive health monitor information may be viewed for each server in the pool. The example below shows an abbreviated view:
show pool [poolname] server hmonstat
+---------------------------------+----------------------------------------+
| Field | Value |
+---------------------------------+----------------------------------------+
| server_hm_stat[1] | |
| server_name | 10.90.15.61:8000 |
| oper_status | |
| state | OPER_UP |
| shm_runtime[1] | |
| health_monitor_name | healthmonitor-1 |
| health_monitor_type | HEALTH_MONITOR_TCP |
| last_transition_timestamp_3 | Tue May 24 20:42:51 2016 ms |
| last_transition_timestamp_2 | Tue May 24 20:42:38 2016 ms |
| last_transition_timestamp_1 | Tue May 24 20:37:10 2016 ms |
| rise_count | 255 |
| fall_count | 0 |
| total_checks | 1414 |
| total_failed_checks | 5 |
| total_count[1] | |
| type | CONNECTION_TIMEOUT |
| count | 5 |
| avg_response_time | 1 |
| recent_response_time | 1 |
| min_response_time | 1 |
| max_response_time | 1999 |
| port | 8000 |
| curr_failed_checks | 1 |
| ip_addr | 10.90.15.61 |
| port | 8000 |
+---------------------------------+----------------------------------------+Via Packet Capture
By default, Avi Vantage does not include health monitor traffic when performing packet captures. This default may be changed via the CLI via the following flags.
debug_vs_hm_include |
Include health monitor packets in the capture |
debug_vs_hm_none |
This default omits health monitor packets from the capture |
debug_vs_hm_only |
Only capture health monitor packets |
Refer to Packet Capture for more help on this topic.
Via Manual Test
It is possible to manually send ping, curl, or similar Linux CLI accessed utilities to validate the response of a server. Refer to Manually Validate Server Health article.
Common Monitor Issues
Review these common issues if the result from a server response is the desired response and Avi Vantage is still marking the server down.
General
- Content returned from servers is inspected and compared to the monitor’s Server Response Data as case sensitive.
- Most monitors only inspect up to 2k within the server response, which includes both headers and content. If the desired result is further within the response, the server will be marked down.
- Duplicate IP is one of the most common issues causing intermittent failures of health checks.
Passive
- The passive monitor will be triggered in the event of a significant error, which will automatically generate logs for the virtual service. When drilling into a server page, the passive monitor may show less than 100%. View the VS logs, filtering for the server in question. Then click the Significance tile from under the Log Analytics sidebar.
-
From the CLI, check to see if failures are occurring and increasing over time:
: > show pool p1 detail | grep suspect | lb_fail_suspect_state | 0
Ping
- Some devices, including servers and firewall, restrict the number or frequency of ICMP messages and may silently discard. If this might be an issue, lower the frequency of the Send Interval.
HTTP
- Servers may be very particular about the exact request headers in the send string. For instance, a space in a host header may cause issues for IIS, such as “Host: Avi Server”.
- The HTTP monitor adds a few headers to emulate a valid request. To omit these extra headers, consider using a TCP monitor, which is explicit to the send string defined in the Client Request Data field. If using TCP, be sure to add \r\n characters for carriage return line feed.
-
Avi Vantage includes \r\n at the end of each line of the request. HTTP 1.0 requires a second \r\n to be sent after the last line, which Avi automatically includes:
[Health monitor send string]\r\n User-Agent: avi/1.0\r\n Host: [Avi inserted server name]\r\n Accept: */*\r\n\r\n - For HTTP/S, Avi Vantage does not render the results, but inspects them literally. For instance, a server may send a 302 Redirect back to Avi Vantage, which does not include “server is good”. A browser will follow the redirect and display the page with the correct content.
- URI encoding of content may also cause an HTTP/S response to fail.
External
-
The external health monitors are run using the user ‘hmuser’ with lower privileges. Attach to a Service Engine and log in as root.
su - hmuser, login as hmuser.root@test-se2:~# su - hmuser hmuser@10-10-25-28:~$ pwd /run/hmuser
Refer to Manually Validate Server Health for more info on attaching to SEs and navigating tenants and namespace.
UDP Health Monitor
UDP health monitors that are configured with no receive-string, rely on ICMP unreachable message to detect an error. The absence of an ICMP message results in the server being marked up. In a deployment with a large number of servers, the number of ICMP messages may be large, and UDP health monitors may be erroneously marked up.
In order to overcome the above situation and mark the Server down or VS down, you can tune the ICMP rate limit configuration.
If ICMP unreachable messages are dropped, in high scale cases due to ICMP unreachable rate-limiter, you can confirm the occurrence of this issue, using the following command:
show serviceengine [se-name] flowtablestat | grep icmp_rx_rl
| icmp_rx_rl_cfg_pps | 100 |
| icmp_rx_rl_confirming | 30 |
| icmp_rx_rl_drops | 0 |
To configure ICMP rate limit the command is :
[admin:controller]: configure serviceengineproperties
[admin:controller]: seproperties:se_runtime_properties
[admin:controller]: seproperties:se_runtime_properties se_rate_limiters
[admin:controller]: seproperties:se_runtime_properties:se_rate_limiters : icmp_rl 100