Auto Scaling Definition
Auto scaling, also referred to as autoscaling, auto-scaling, and sometimes automatic scaling, is a cloud computing technique for dynamically allocating computational resources. Depending on the load to a server farm or pool, the number of servers that are active will typically vary automatically as user needs fluctuate.
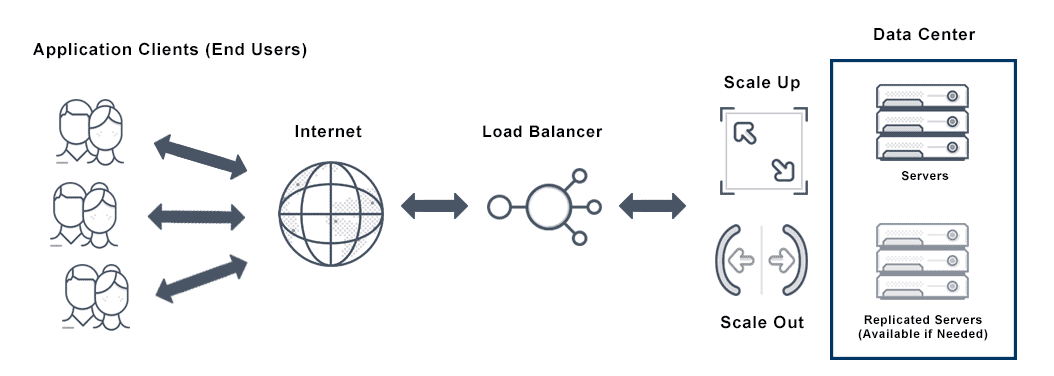
Auto scaling and load balancing are related because an application typically scales based on load balancing serving capacity. In other words, the serving capacity of the load balancer is one of several metrics (including cloud monitoring metrics and CPU utilization) that shapes the auto scaling policy.
What is Auto Scaling in Cloud Computing?
Autoscaling is a cloud computing feature that enables organizations to scale cloud services such as server capacities or virtual machines up or down automatically, based on defined situations such as traffic ir utilization levels. Cloud computing providers, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), offer autoscaling tools.
Core autoscaling features also allow lower cost, reliable performance by seamlessly increasing and decreasing new instances as demand spikes and drops. As such, autoscaling provides consistency despite the dynamic and, at times, unpredictable demand for applications.
The overall benefit of autoscaling is that it eliminates the need to respond manually in real-time to traffic spikes that merit new resources and instances by automatically changing the active number of servers. Each of these servers requires configuration, monitoring and decommissioning, which is the core of autoscaling.
For instance, when such a spike is driven by a distributed denial of service (DDoS) attack, it can be difficult to recognize. More efficient monitoring of autoscaling metrics and better autoscaling policies can sometimes help a system respond quickly to this issue. Similarly, an auto scaling database automatically scales capacity up or down, starts up, or shuts down based on the needs of an application.
Important Auto Scaling Terminologies
An instance is a single server or machine that is subject to auto scaling rules created for a group of machines. The group itself is an auto scaling group, with each instance in the group subject to those auto scaling policies.
For example, the Elastic Compute Cloud (EC2) is the compute platform of the AWS ecosystem. EC2 instances offer scalable, customizable server options within the AWS cloud. Amazon EC2 instances are virtual, elastically scaled on demand, and seamless to the end user.
An auto scaling group is a logical collection of Amazon EC2 instances for automatic scaling purposes. Each Amazon EC2 instance in the group will be subject to the same auto scaling policies.
Auto scaling group size refers to the number of instances in the auto scaling group. Desired capacity or size is the ideal number of instances in that auto scaling group. If there is a difference between those two numbers, the auto scaling group can either instantiate (provision and attach) new instances or remove (detach and terminate) instances.
Depending on the rules and auto scaling algorithms controlling a particular auto scaling group, minimum and maximum size threshold values set cutoff points above or below which instance capacity should not rise or fall. An auto scaling policy also often specifies any changes to the auto scaling group’s desired capacity in response to metrics breaching set thresholds.
Auto scaling policies often have associated cooldown periods to ensure the entire system continues to manage traffic. Auto scaling cooldown periods add time after specific scaling actions to allow newly instantiated instances time to begin to manage traffic.
Changes to an auto scaling group’s desired capacity might be fixed or incremental. Fixed changes simply provide a desired capacity value. Incremental changes decrease or increase by a specific number rather than setting an end value. Scaling up policies, also called scaling out policies, increase desired capacity. Scaling down policies, also called scaling in policies, decrease desired capacity.
To determine whether attached instances are functioning properly, an auto scaling group conducts a health check. Unhealthy instances should be marked for replacement.
Elastic load balancing software can conduct health checks. Amazon EC2 status checks are also an option, as are custom health checks. A positive health check can be based on whether the instance remains registered and in service with its associated load balancer, or whether the instance is still reachable and exists.
Launch configuration describes the scripts and parameters needed to launch a new instance. This includes the instance type, machine image, potential availability zones for launch, purchase options (such as spot vs. on-demand), and scripts to run upon launch.
What is the Difference Between Auto Scaling and Load Balancing?
Elastic load balancing and application autoscaling are closely related. Both application auto scaling and load balancing reduce backend tasks such as monitoring the health of servers, managing the traffic load among the servers, and increasing or reducing servers pursuant to requirements. In fact, it is common to see solutions that include a load balancer with autoscaling features. However, elastic load balancing and auto scaling are distinct concepts.
An application load balancer auto scaling package works in tandem as follows. You can deploy an auto scaling group load balancer to improve availability and performance, and decrease application latency. This works because you can define your autoscaling policies based on your application requirements to scale-in and scale-out instances and thus instruct how the load balancer distributes the traffic load between the running instances.
Autoscaling allows a user to set a policy based on predefined criteria that manage the number of available instances in both peak and off-peak hours. This enables multiple instances with the same functionality—parallel capabilities increasing or decreasing depending on demand.
In contrast, an elastic load balancer simply checks the health of each instance, distributes traffic, and connects each request to appropriate target groups. If it detects an unhealthy instance, an elastic load balancer stops traffic to that instance and sends data requests elsewhere. It also prevents any one instance from being swamped by requests.
Autoscaling with elastic load balancing works by attaching a load balancer and an autoscaling group so it can route all requests to all instances equally. This frees the user from monitoring the number of endpoints the instances create—another difference between autoscaling and load balancing in terms of how they work alone.
Advantages of Auto Scaling
Auto scaling provides several advantages:
Cost. When loads are low, auto scaling allows both companies managing their own infrastructure and businesses that rely on cloud infrastructure to send some servers to sleep. This reduces electricity costs and water costs where water is used in cooling. Cloud auto scaling also means paying for total usage instead of maximum capacity.
Security. Auto scaling also protects against application, hardware, and network failures by detecting and replacing unhealthy instances while still providing application resiliency and availability.
Availability. Auto scaling improves availability and uptime, especially when production workloads are less predictable.
While many businesses have a set daily, weekly, or yearly cycle to govern server use, auto scaling is different in that it reduces the chance of having too many or too few servers for the actual traffic load. This is because auto scaling is responsive to actual usage patterns, in contrast to a static scaling solution.
For example, a static scaling solution might rely on the idea that traffic is typically lower at 2:00 am, and send some servers to sleep at that time. However, in practice there may be spikes at that time—perhaps during a viral news event or other unexpected times.
Predictive Autoscaling vs Scheduled Autoscaling
By default, autoscaling is a reactive approach to decision making. It scales traffic as it responds in real-time to changes in traffic metrics. However, in certain situations, especially when changes happen very quickly, it may be less effective to take a reactive approach.
Scheduled autoscaling is a kind of hybrid approach to scaling policy that still functions in real-time, but also anticipates known changes in traffic loads and executes policy reactions to those changes at specific times. Scheduled scaling works best in cases where there are known traffic decreases or increases at particular times of day, but the changes in question are typically very sudden. Different from static scaling solutions, scheduled scaling keeps autoscaling groups “on notice” to respond quickly during key times with added capacity.
Predictive autoscaling deploys predictive analytics, including historical usage data and recent usage trends, to autoscale based on predictions about usage in the future. Predictive autoscaling is especially useful for:
- Detecting large, imminent spikes in demand and readying capacity slightly in advance
- Coping with large-scale, regional outages
- Offering more flexibility in scaling out or in to respond to variable traffic patterns throughout the day
Horizontal Auto Scaling vs Vertical Auto Scaling
Horizontal auto scaling refers to adding more servers or machines to the auto scaling group in order to scale. Vertical auto scaling means scaling by adding more power rather than more units, for example in the form of additional RAM.
There are several issues to consider when considering horizontal auto scaling vs vertical auto scaling.
Because it involves adding more power to an existing machine, there are inherent architectural challenges to vertical auto scaling. There is no redundant server, and application health is tied to the machine’s single location. Vertical scaling also demands downtime for reconfigurations and upgrades. Finally, vertical auto scaling enhances performance, but not availability.
Decoupling application tiers may mitigate part of the vertical scaling challenge, because application tiers are likely to use resources and grow at different rates. Stateless servers are best able to handle requests for a better user experience, and add more instances to tiers. This also allows you to use elastic load balancing to scale incoming requests across instances more efficiently.
When there are thousands of users, vertical scaling cannot handle the requests. In these cases, horizontal auto scaling adds more machines to the resource pool. Load balancing, distributed file systems, and clustering are all part of effective horizontal auto scaling.
Stateless servers are important for applications which typically have many users. User sessions should ideally never be tied to one server, and should instead be able to move seamlessly across many servers while maintaining a single session. This kind of browser-side session storage allows for better user experience and is one of the results of good horizontal scaling.
A service-oriented architecture for applications should include logical blocks that interact yet are self-contained. This way, you can scale blocks out singly based on need. Tiers for applications, caching, database, and web should all be independent pieces of microservice architecture to save both vertical and horizontal scaling costs.
Horizontal auto scaling does not demand downtime, in that it creates independent new instances. It also increases availability as well as performance due to this independence.
Remember: vertical scaling doesn’t work for every organization or workload. Many users create a demand for horizontal scaling, and a single instance versus many smaller instances will perform differently on the same total resource depending on user needs.
For emergencies and unplanned events, the multiple instances created by horizontal auto scaling may increase resiliency. For this reason, it is often the preferred approach for cloud-based businesses.

Does VMware NSX Advanced Load Balancer offer Auto Scaling Solutions?
The VMware NSX Advanced Load Balancer delivers predictive auto scaling and elastic load balancing. The Controller can scale both application instances and load balancers based on application usage and traffic patterns.
Legacy, appliance-based application delivery controllers (ADCs) can become the bottlenecks because their capacity is static and cannot scale dynamically. The VMware NSX Advanced Load Balancer resolves this issue by matching traffic patterns, enabling dynamic scaling of resources.
Learn how to enforce auto scale thresholds for vertical or horizontal resource scaling in real time.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.