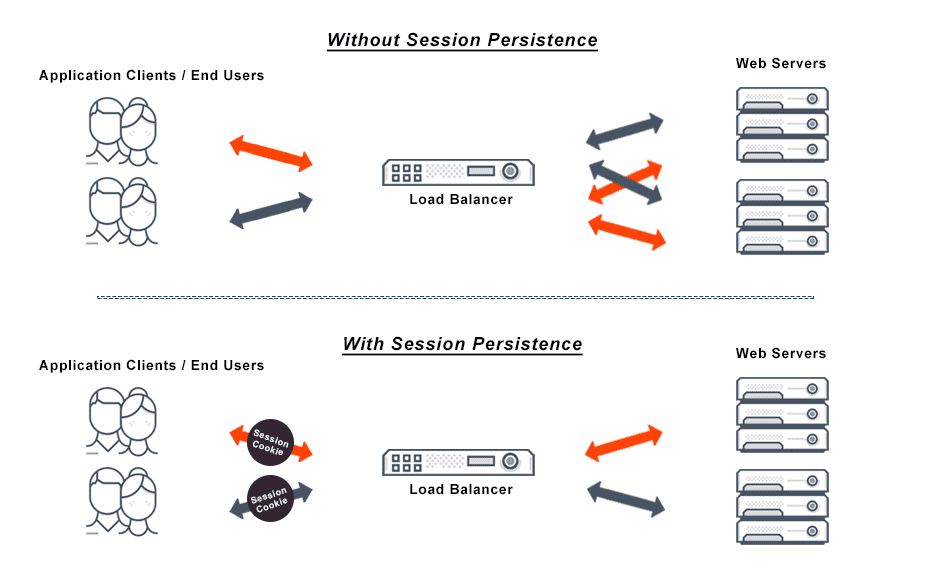
Static Load Balancing Definition
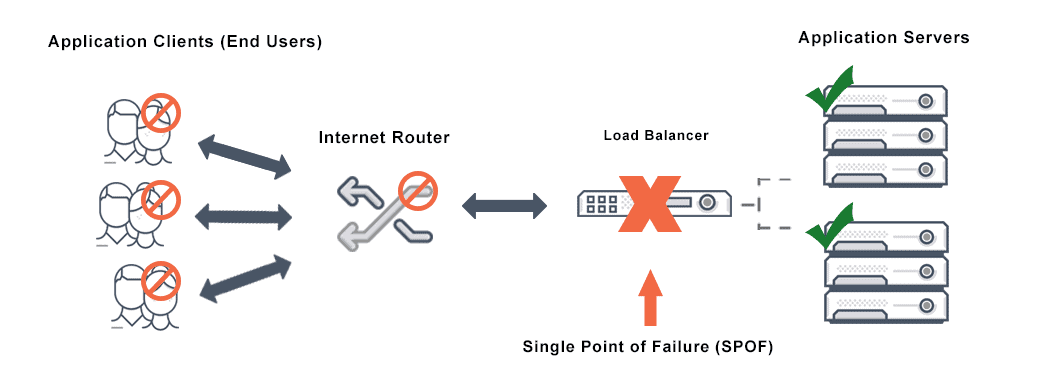
A load balancer is a hardware device or software platform that prevents single servers from becoming overloaded. Load balancers use algorithms to distribute network traffic between servers. An algorithm is the logic or set of predefined rules used for sorting, and load balancing algorithms can be static or dynamic.
Static load balancing algorithms in cloud computing do not account for the state of the system, or measures such as load level of processors, as they distribute tasks. Static algorithms divide traffic equally among servers or based on other rules that are not sensitive to system states and are therefore intended for systems with very little variation in load. Static load balancing algorithms demand in-depth knowledge of server resources at the time of implementation for better processor performance.
Dynamic load balancing algorithms require real-time communication with the network because they identify the lightest server and give it preference. The dynamic algorithm controls the load based on the present state of the system and transfers traffic to underutilized machines from highly utilized machines in real-time.

What is Static Load Balancing?
A load balancer is a hardware or software device that effectively distributes traffic across healthy servers to prevent any one server from becoming overloaded. There are two basic approaches to load balancing: static load balancing and dynamic load balancing.
The difference between static and dynamic load balancing
Static load balancing methods distribute traffic without adjusting for the current state of the system or the servers. Some static algorithms send equal amounts of traffic, either in a specified order or at random, to each server in a group. Dynamic load balancing algorithms account for the current state of the system and each server and base traffic distribution on those factors.
A static load balancing algorithm does not account for the state of the system as it distributes tasks. Instead, distribution is shaped by assumptions and knowns about the overall system made before sorting starts. This includes knowns such as the number of processors and communication speeds and power, and assumptions such as resource requirements, response times, and arrival times of incoming tasks.
Static load balancing algorithms in distributed systems minimize specific performance functions by associating a known set of tasks with available processors. These types of load balancing strategies typically center around a router that optimizes the performance function and distributes loads. The benefit of static load balancing in distributed systems is ease of use and quick, simple deployment, although there are some situations that are not best served by this kind of algorithm.
Dynamic algorithms account for the current load of each node or computing unit in the system, achieving faster processing by moving tasks dynamically away from nodes that are overloaded toward nodes that are underloaded. Dynamic algorithms are far more complicated to design, but especially when execution times for different tasks vary greatly, they can produce superior results. Furthermore, because there is no need to dedicate specific nodes to work distribution, a dynamic load balancing architecture is often more modular.
Unique assignment of tasks involves tasks that are assigned uniquely to a processor based on its state at a particular moment. Dynamic assignment refers to the permanent redistribution of tasks based on the state of the system and its evolution. Obviously, any load balancing algorithm can actually slow down the overall process if it demands excessive communication to reach decisions.
Both dynamic and static load balancing techniques are shaped by other factors as well:
Nature of tasks. The nature of the tasks has a major impact on the efficiency of load balancing algorithms, so maximizing access to task information as algorithm decision making takes place increases optimization potential.
Task size. Exact knowledge of task execution time is extremely rare, but would enable optimal load distribution. There are several ways to estimate various execution times. Where tasks are similarly sized, an average execution time might be used successfully. However, more sophisticated techniques are required when execution times are very irregular. For example, it is possible to add metadata to tasks and then make inferences for future tasks based on statistics based on the previous execution time for similar metadata.
Dependencies. Tasks may depend on each other, and some cannot start until others are completed. Illustrate such interdependencies with a directed acyclic graph and minimize total execution time by optimizing task order. Some algorithms can use metaheuristic methods to calculate optimal task distributions.
Segregation of tasks. This refers to the ability of tasks to be broken down into subtasks during execution because this specificity is important in the design of load balancing algorithms.
Hardware architecture among parallel units:
- Heterogeneity. Units of different computing power often comprise parallel computing infrastructures, and load distribution must account for this variation. For example, units with less computing power should receive requests that demand less computation, or fewer requests of homogeneous or unknown size than larger units.
- Memory. Parallel units are often divided into categories of shared and distributed memory. Shared memory units follow the PRAM model, all sharing, reading, and writing in parallel on one, common memory. Distributed memory units follow the distributed memory model, each unit exchanging information via messages and having its own memory. There are advantages to either type, but few systems fall squarely into one category or the other. In general, load balancing algorithms should be adapted specifically to a parallel architecture to avoid reducing efficiency of parallel problem solving.
Hierarchy. The two main types of load balancing algorithms are controller-agent and distributed control. In the controller-agent model, the control unit assigns tasks to agents who execute the tasks and inform the controller of progress. The controller can assign or reassign tasks, in case of dynamic algorithms. When control is distributed between nodes, the nodes share responsibility for assigning tasks, and the load balancing algorithm is executed on each of them. An intermediate strategy, with control nodes for sub-clusters, all under the purview of a global control, is also possible. In fact, various multi-level strategies and organizations, using elements of both distributed control and control-agent strategies, are possible.
Scalability. Computer architecture evolves, but it is better to avoid designing a new algorithm with every change to the system. Thus, the scalability of the algorithm, or its ability to adapt to a scalable hardware architecture, is a critical parameter. An algorithm is scalable for an input parameter when the size of the parameter and the algorithm’s performance remain relatively independent. The algorithm is called moldable when it can adapt to a varying number of computing units, but the user must select the number of computing units before execution. Finally, the algorithm is malleable if it can deal with a changing number of processors during execution.
Fault tolerance. The failure of a single component should never cause the failure of the entire parallel algorithm during execution, especially in large-scale computing clusters. Fault tolerant algorithms help detect problems while recovery is still possible.
Approaches to Static Load Balancing
In most static load distribution scenarios, there is not significant prior knowledge about the tasks. However, static load distribution is always possible, even if the execution time is not known in advance.
Round Robin. Among the most used and simplest load balancing algorithms, round robin load balancing distributes client requests to application servers in rotation. It passes client requests in the order it receives them to each application server in turn, without considering their characteristics such as computing ability, availability, and load handling capacity.
Weighted Round Robin. A weighted round robin load balancing algorithm accounts for various application server characteristics within the context of the basic round robin load balancing algorithm. The algorithm distributes traffic in turn, but also giving preference to units the administrator “weights” based on chosen criteria—usually ability to handle traffic. Instead of a classic round robin 1 by 1 distribution to every server in turn, weighted units would receive more requests during their turns.
Opportunistic/Randomized Static. Opportunistic/randomized algorithms randomly assign tasks to the various servers without regard to current workload. This works better for smaller tasks, and performance falls as task size increases. At times bottlenecks arise, in part due to the randomness of the distribution. At any time a machine with a high load might randomly be assigned a new task, making the problem worse.
Most other strategies, such as consistent hash to selected IP addresses, fastest response, fewest servers, fewest tasks, least connections, least load, weighted least connection, and resource-based adaptive, are dynamic load balancing algorithms.
Does Avi Offer Static Load Balancing?
Yes. Avi is a complete load balancing solution. The heart of a load balancer is its ability to effectively distribute traffic across healthy servers. Avi provides a number of algorithms, each with characteristics that may be best suited for one use case versus another. Avi delivers multi-cloud application services including a software load balancer that helps ensure a fast, scalable, and secure application experience.
For more on the implementation of load balancers, check out our Application Delivery How-To Videos.