Single Point of Failure Definition
A SPOF or single point of failure is any non-redundant part of a system that, if dysfunctional, would cause the entire system to fail. A single point of failure is antithetical to the goal of high availability in a computing system or network, a software application, a business practice, or any other industrial system.
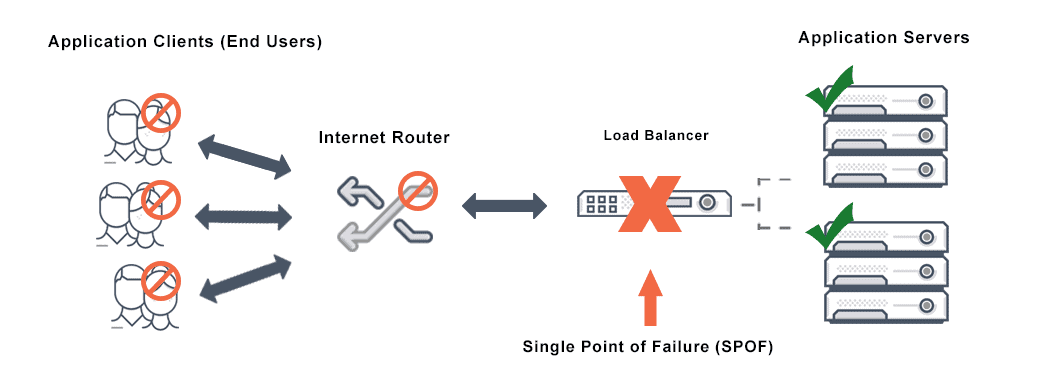
What is a Single Point of Failure?
A single point of failure (SPOF) is essentially a flaw in the design, configuration, or implementation of a system, circuit, or component that poses a potential risk because it could lead to a situation in which just one malfunction or fault causes the whole system to stop working. Depending on the interdependencies implicated in the failure and its location, a single point of failure in a data center may compromise workload availability or even the availability of the entire location. Productivity and business continuity decrease, and security is compromised.
Single points of failure are undesirable to systems that demand high availability and reliability, such as supply chains, networks, and software applications. SPOFs are possible in both software and hardware layouts in the context of cloud computing.
To make a circuit or system more robust, audit for single points of failure. This way, the organization can plan to add redundancy at each level where a SPOF currently exists. Highly available systems should never rely on single components.
High-availability clusters and both physical redundancy and logical redundancy are key to avoiding SPOFs. If a system component fails, another component should immediately take its place. For example, a database in multiple locations can be accessed even if one location fails. It is important to identify software flaws that can cause outages and eliminate software-based single points of failure in cloud architecture.
How to Eliminate Single Points of Failure
To eliminate single points of failure, first identify potential risk posed by conducting a single point of failure risk assessment across three main areas: hardware, software/providers/services, and people. Create a single point of failure analysis checklist detailing the general areas for assessment.
In each category, the IT team should conduct SPOF analysis and search for any unmonitored devices on the network, any software or hardware systems or providers that have no redundancy, people that cannot be replaced in case of emergency, and any data that isn’t backed up. For each network component, identify what would be lost if that particular piece went down as part of your single point of failure analysis.
Achieve redundancy in computing at the internal component level, at the system level with multiple machines, or at site level with more than one location to avoid single points of failure.
Each individual server within a high-availability server cluster may achieve redundancy by having multiple hard drives, power supplies, and other components.
At the system level, ensure high availability for the server cluster with a load balancer. Spare servers can also deploy in case of failure to achieve system level redundancy.
At the personnel level, a single point of failure person has access to something no one else does, or conducts business critical tasks that no one else can handle.
Obviously, a data center itself supports other operations including business logic. As such, it is in itself a potential single point of failure for the business, if its functions cannot be replicated elsewhere. Achieving this kind of replication is typically the focus of an IT disaster resiliency, continuity plan, or recovery program.
Packet switching, used by “survivable communications networks” such as the internet and ARPANET, is designed to have no single point of failure. It works by allowing multiple routes between any two destinations on the network. This enables users to communicate as the packets “route around” damage even when nodes in between them fail.
Microservices architecture can also reduce the risk of potential SPOFs, in that this type of structure distributes the functionality of a system in many places. This prevents the entire system from failing when a part of it stops working.
Network protocols intended to avoid single points of failure include:
- Intermediate System to Intermediate System
- Open Shortest Path First
- Shortest Path Bridging
Threat Protection and Load Balancer Single Point of Failure
Almost any tool can be a SPOF hazard, including security tools. Advanced threat protection tools such as web application firewalls (WAF), load balancers, intrusion prevention systems (IPS), and advanced threat protection (ATP) solutions are at risk during link or NIC failure, during power failures, or when they either block good traffic or pass bad traffic. During these times they are vulnerable to both common threats such as brute force attacks and more complex threats such as cross-site request forgery or implementing XML external entities.
Because even these security tools can fail to protect the network, redundant security measures are essential. There are ways to configure WAF security architecture that minimize the frequency and effectiveness of various attacks and avoid single points of failure. For example, although basic secure single-tier or two-tier web application architectures are useful during project development, they introduce a SPOF.
Instead, a multi-tier or N-tier architecture offers compartmentalization, separating different application components according to their functions into multiple tiers. With each tier running on a different system, there is no single point of failure. In this sense, multiple, properly configured load balancers can be a single point of failure solutions rather than a source of the problem.
How Does Avi’s Platform Help Eliminate Single Points of Failure?
Avi platform’s load balancing capabilities keeps systems online reliably and reduces the chances of a single point of failure by automatically redistributing traffic, instantiating virtual services in a self-healing manner when one fails, and handling workload additions or moves. These solutions can be configured for high availability load balancing in various modes, as well.
Learn more about how the Avi Networks platform helps reduce risk from SPOFs here.
For more on the actual implementation of load balancers, check out our Application Delivery How-To Videos.