Kubernetes Ingress Services Definition
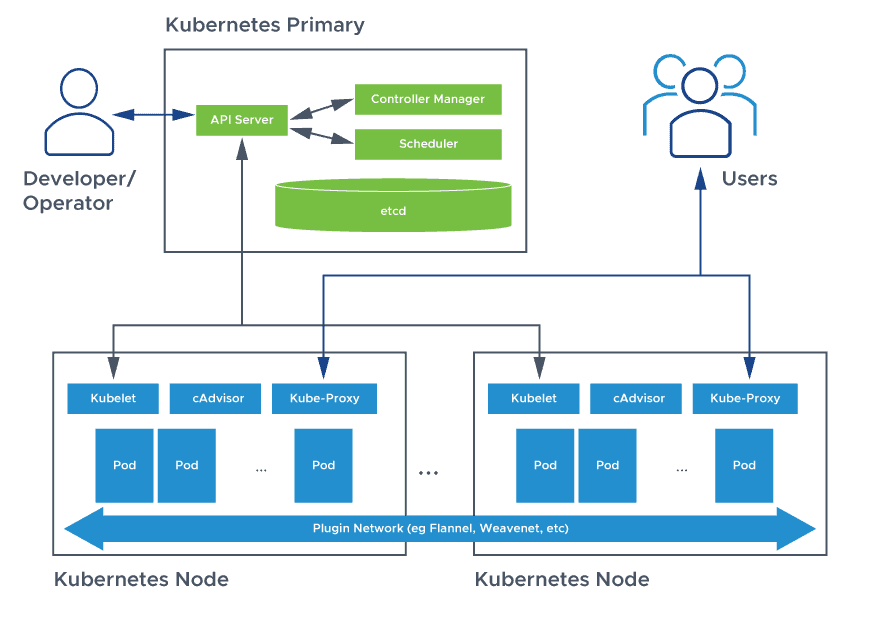
In Kubernetes, an ingress is an API object that manages external IP access to services in a cluster, typically exposing outside HTTP and HTTPS routes to services inside the cluster. A set of rules the ingress resource defines controls traffic routing. Ingress may be configured to offer services SSL/TLS termination, traffic load balancing, externally-reachable URLs, and virtual, name-based hosting.
Typically an Ingress controller, usually with a load balancer, is responsible for fulfilling the ingress, though it may also configure additional frontends such as an edge router to assist in managing traffic. Ingress allows for traffic routing and access without exposing every node on the service or creating multiple load balancers.
An Ingress does not expose random protocols or ports. To expose services beyond HTTP and HTTPS to the internet, generally a nodeport or load balancer are required.
Kubernetes Ingress Services FAQs
What is Kubernetes Ingress Services?
A Kubernetes cluster is made up of node machines. Inside pods grouped based on the type of service they provide, these machines run containerized applications. A set of pods must be capable of accepting connections from inside or outside the cluster. Yet both internal and external access are challenging.
The node’s IP address cannot access pods inside the cluster for external access, yet users must communicate with the application using the node’s IP address. And while each pod in the system has its own unique Pod IP assigned, these are unreliable for internal communication because they are not static. This means persistent internal and external access for the cluster is critical.
A service is a Kubernetes object that acts as a stable address for pods, serving as an endpoint enabling communication between components inside and outside the application.The three important Kubernetes service types are:
- ClusterIP
- NodePort
- Load Balancer
These all allow users to expose a service to external network requests and send requests from outside the Kubernetes cluster to services inside the cluster.
ClusterIP
The default ingress service in Kubernetes is ClusterIP. Unless the user manually defines another type, a service will be exposed on a ClusterIP.
NodePort
Declare the NodePort configuration setting in a service YAML. This causes Kubernetes to allocate and forward any request to the cluster to a specific port on each node.
It is simple to manage services with a NodePort. The Kubernetes API assigns requests to random TCP ports and exposes them outside the cluster. This is convenient because a client can target any cluster node via one port and ensure that messages land.
However, this is also a less robust method. There is no way to know to which port a service will be allocated, and ports can be re-allocated. Furthermore, port values must fall between 30000 and 32767, a range that is both out of range of well-known ports and non-standard compared to familiar 80 and 443 ports for HTTP and HTTPS. The randomness itself presents a challenge, particularly for configuring firewall rules, NAT, etc. when a different port is randomly set for each service.
Load Balancer
By specifying the property type in the service’s YAML the same way the NodePort is set, users can set a service to be the load balancer type. A load balancer spreads workloads evenly across Kubernetes clusters.
Kubernetes service ingress load balancers sit between servers and the internet, connecting users and exposing services to the outside world, while also providing failover. Should a server fail, the load balancer reduces the effect on users by redirecting the workload to a backup server, and sending user requests to whichever servers are available. They add servers when demand is high, and drop them when demand falls. However, many services demand high numbers of load balancers, because each service requires its own.
However, there are prerequisites for this approach, which depends on the functionality of an external load balancer in the cluster, typically via a cloud provider. Each cloud-hosted environment such as Amazon’s EKS and Google’s GKE spins up its own hosted load balancer technology, along with a new public IP address.
While users may expose a service with Nodeport and LoadBalancer by specifying a value in the service’s type, relative to the service and service type, Kubernetes ingress service is a completely independent resource. Isolated and decoupled from services to expose, users create, declare, and destroy ingress separate from services with rules consolidated in one location.
Just like any other application, ingress controllers are pods. This means they can see other sets of pods and are part of the cluster. Ingress controllers are built using underlying reverse proxies with various performance specifications and features, such as Layer 7 routing and load balancing capabilities.
Like other Kubernetes pods inside the cluster, ingress controllers are susceptible to the same rules for exposure via a Service: they require either a LoadBalancer or NodePort for access. However, to contrast Kubernetes service load balancers vs ingress controllers, the controller can route traffic through one single service and then connect to many internal pods. The ingress controller can inspect HTTP requests and direct them to the correct pods based on the domain name, the URL path, or other observed characteristics.
Ingress service in Kubernetes takes a declarative approach that allows users to specify what they want but leaves fulfillment to the Ingress Controller, which configures its underlying proxy to enact any new ingress rules and corresponding routes it detects.
The need to configure an ingress controller for a Kubernetes cluster is a disadvantage to this approach. However, this is simple with the VMware NSX Advanced Load Balancer Kubernetes ingress controller, the Nginx ingress controller, or another Kubernetes ingress services solution. Many of the options on the market are open-source, and many are compatible with each other. In other words, there is no single Azure Kubernetes service ingress controller, or Google GKE Kubernetes ingress controller, but instead a range of potential compatible options.
Kubernetes Ingress vs Service
There is a difference between ingress and service in Kubernetes. A Kubernetes service is a logical abstraction for a group of pods which perform the same function deployed in a cluster. A service enables a group of pods, which are ephemeral, to provide specific functions such as image processing or web services, with an assigned name and ClusterIP, a unique IP address.
By using a cluster-internal IP, Kubernetes’ default service type, ClusterIP limits access to the service to within the cluster. ClusterIP allows pods to communicate with each other inside a cluster, only.
Users can also set NodePort as the service type as another Kubernetes networking option. NodePort allows users to configure load balancers to support environments Kubernetes does not support completely. NodePort opens up a way for external traffic to reach the nodes by exposing their IP addresses.
This brings us to the difference between service and ingress in Kubernetes. An ingress vs service in Kubernetes is an API object that manages outside access to Kubernetes cluster services, generally via HTTPS/HTTP, by providing routing rules. Users can consolidate routing rules into a single custom resource and create a set of rules for moving traffic without multiple load balancers or exposing each service on the node with ingress routes.
Comparing the NodePort or LoadBalancer Kubernetes services vs ingress, ingress is an entry point that rests in front of multiple services in the cluster, not a type of service. NodePorts are simple to use and convenient, especially at the dev/test stage, but compared to Kubernetes ingress services they have many weaknesses. Here are some of the other Kubernetes ingress and service differences:
- To reach the service, clients must know node IP addresses; ingress makes hiding cluster internals such as numbers and IP addresses of nodes and using a DNS entry simpler
- NodePort increases the complexity of secure Kubernetes cluster management because it demands opening external port access to each node in the cluster for every service
- Using NodePort with a proliferation of clusters and services, reasoning about network access and troubleshooting rapidly become very complex
Finally, consider the difference between a Kubernetes deployment vs service vs ingress. A Kubernetes deployment refers to the file that defines the desired characteristics or behavior of the pod itself. For example, a Kubernetes deployment might instruct Kubernetes to automatically upgrade the pod’s container image version so there’s no need to do it manually. A Kubernetes deployment is a management tool for pods.
Does VMware NSX Advanced Load Balancer Offer Kubernetes Ingress Service Discovery?
Yes. VMware NSX Advanced Load Balancer’s advanced platform serves as a Kubernetes ingress controller with advanced application services. Appliance-based load balancing solutions are obsolete in the face of modern, microservices-based application architectures. Containerized applications deployed in Kubernetes clusters need enterprise-class, scalable Kubernetes Ingress Services for global and local traffic management, load balancing, monitoring/analytics, service discovery, and security.
VMware NSX Advanced Load Balancer’s advanced Kubernetes ingress controller delivers enterprise-grade features, multi-cloud application services, high levels of machine learning-based automation, and observability—all designed to help bring container-based applications into enterprise production environments. Learn more here.
For more on the actual implementation of load balancers, check out our Application Delivery How-To Videos.