Configure the Kubernetes API server securely. Disable anonymous/unauthenticated access and use TLS encryption for connections
Kubernetes Architecture Definition
Kubernetes is an open source container deployment and management platform. It offers container orchestration, a container runtime, container-centric infrastructure orchestration, load balancing, self-healing mechanisms, and service discovery. Kubernetes architecture, also sometimes called Kubernetes application deployment architecture or Kubernetes client server architecture, is used to compose, scale, deploy, and manage application containers across host clusters.
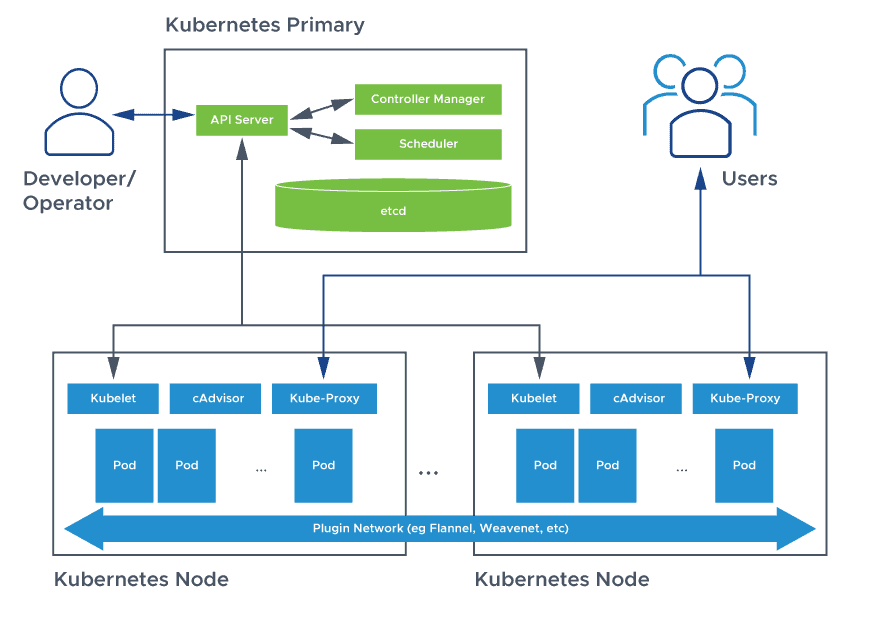
An environment running Kubernetes consists of the following basic components: a control plane (Kubernetes control plane), a distributed key-value storage system for keeping the cluster state consistent (etcd), and cluster nodes (Kubelets, also called worker nodes or minions).
What is Kubernetes Architecture?
A Kubernetes cluster is a form of Kubernetes deployment architecture. Basic Kubernetes architecture exists in two parts: the control plane and the nodes or compute machines. Each node could be either a physical or virtual machine and is its own Linux environment. Every node also runs pods, which are composed of containers.
Kubernetes architecture components or K8s components include the Kubernetes control plane and the nodes in the cluster. The control plane machine components include the Kubernetes API server, Kubernetes scheduler, Kubernetes controller manager, and etcd. Kubernetes node components include a container runtime engine or docker, a Kubelet service, and a Kubernetes proxy service.
Kubernetes Control Plane
The control plane is the nerve center that houses Kubernetes cluster architecture components that control the cluster. It also maintains a data record of the configuration and state of all of the cluster’s Kubernetes objects.
The Kubernetes control plane is in constant contact with the compute machines to ensure that the cluster runs as configured. Controllers respond to cluster changes to manage object states and drive the actual, observed state or current status of system objects to match the desired state or specification.
Several major components comprise the control plane: the API server, the scheduler, the controller-manager, and etcd. These core Kubernetes components ensure containers are running with the necessary resources in sufficient numbers. These components can all run on one primary node, but many enterprises concerned about fault tolerance replicate them across multiple nodes to achieve high availability.
Kubernetes API Server
The front end of the Kubernetes control plane, the API Server supports updates, scaling, and other kinds of lifecycle orchestration by providing APIs for various types of applications. Clients must be able to access the API server from outside the cluster, because it serves as the gateway, supporting lifecycle orchestration at each stage. In that role, clients use the API server as a tunnel to pods, services, and nodes, and authenticate via the API server.
Kubernetes Scheduler
The Kubernetes scheduler stores the resource usage data for each compute node; determines whether a cluster is healthy; and determines whether new containers should be deployed, and if so, where they should be placed. The scheduler considers the health of the cluster generally alongside the pod’s resource demands, such as CPU or memory. Then it selects an appropriate compute node and schedules the task, pod, or service, taking resource limitations or guarantees, data locality, the quality of the service requirements, anti-affinity and affinity specifications, and other factors into account.
Kubernetes Controller Manager
There are various controllers in a Kubernetes ecosystem that drive the states of endpoints (pods and services), tokens and service accounts (namespaces), nodes, and replication (autoscaling). The controller manager—sometimes called cloud controller manager or simply controller—is a daemon which runs the Kubernetes cluster using several controller functions.
The controller watches the objects it manages in the cluster as it runs the Kubernetes core control loops. It observes them for their desired state and current state via the API server. If the current and desired states of the managed objects don’t match, the controller takes corrective steps to drive object status toward the desired state. The Kubernetes controller also performs core lifecycle functions.
ETCD
Distributed and fault-tolerant, etcd is an open source, key-value store database that stores configuration data and information about the state of the cluster. etcd may be configured externally, although it is often part of the Kubernetes control plane.
etcd stores the cluster state based on the Raft consensus algorithm. This helps cope with a common problem that arises in the context of replicated state machines and involves multiple servers agreeing on values. Raft defines three different roles: leader, candidate, and follower, and achieves consensus by electing a leader.
In this way, etcd acts as the single source of truth (SSOT) for all Kubernetes cluster components, responding to queries from the control plane and retrieving various parameters of the state of the containers, nodes, and pods. etcd is also used to store configuration details such as ConfigMaps, subnets, and Secrets, along with cluster state data.
Kubernetes Cluster Architecture
Managed by the control plane, cluster nodes are machines that run containers. Each node runs an agent for communicating with the control plane, the kubelet—the primary Kubernetes controller. Each node also runs a container runtime engine, such as Docker or rkt. The node also runs additional components for monitoring, logging, service discovery, and optional extras.
Here are some Kubernetes cluster components in focus:
Nodes
A Kubernetes cluster must have at least one compute node, although it may have many, depending on the need for capacity. Pods orchestrated and scheduled to run on nodes, so more nodes are needed to scale up cluster capacity.
Nodes do the work for a Kubernetes cluster. They connect applications and networking, compute, and storage resources.
Nodes may be cloud-native virtual machines (VMs) or bare metal servers in data centers.
Container Runtime Engine
Each compute node runs and manages container life cycles using a container runtime engine. Kubernetes supports Open Container Initiative-compliant runtimes such as Docker, CRI-O, and rkt.
Kubelet service
Each compute node includes a kubelet, an agent that communicates with the control plane to ensure the containers in a pod are running. When the control plane requires a specific action happen in a node, the kubelet receives the pod specifications through the API server and executes the action. It then ensures the associated containers are healthy and running.
Kube-proxy service
Each compute node contains a network proxy called a kube-proxy that facilitates Kubernetes networking services. The kube-proxy either forwards traffic itself or relies on the packet filtering layer of the operating system to handle network communications both outside and inside the cluster.
The kube-proxy runs on each node to ensure that services are available to external parties and deal with individual host subnetting. It serves as a network proxy and service load balancer on its node, managing the network routing for UDP and TCP packets. In fact, the kube-proxy routes traffic for all service endpoints.
Pods
Until now, we have covered concepts that are internal and infrastructure-focused. In contrast, pods are central to Kubernetes because they are the key outward facing construct that developers interact with.
A pod represents a single instance of an application, and the simplest unit within the Kubernetes object model. However, pods are central and crucial to Kubernetes. Each pod is composed of a container or tightly coupled containers in a series that logically go together, along with rules that control how the containers run.
Pods have a limited lifespan and eventually die after upgrading or scaling back down. However, although they are ephemeral, pods can run stateful applications by connecting to persistent storage.
Pods are also capable of horizontal autoscaling, meaning they can grow or shrink the number of instances running. They can also perform rolling updates and canary deployments.
Pods run together on nodes, so they share content and storage and can reach other pods via localhost. Containers may span multiple machines, so pods may as well. One node can run multiple pods, each collecting multiple containers.
The pod is the core unit of management in the Kubernetes ecosystem and acts as the logical boundary for containers that share resources and context. Differences in virtualization and containerization are mitigated by the pod grouping mechanism, which enables running multiple dependent processes together.
Achieve scaling in pods at runtime by creating replica sets, which deliver availability by constantly maintaining a predefined set of pods, ensuring that the deployment always runs the desired number. Services can expose a single pod or a replica set to external or internal consumers.
Services associate specific criteria with pods to enable their discovery. Pods and services are associated through key-value pairs called selectors and labels. Any new match between a pod label and selector will be discovered automatically by the service.
Additional Kubernetes Web Application Architecture Components
Kubernetes manages an application’s containers, but it can also manage a cluster’s attached application data. Kubernetes users can request storage resources without knowing underlying storage infrastructure details.
A Kubernetes volume is just a directory that is accessible to a pod, which may hold data. The contents of the volume, how it comes to be, and the medium that backs it are determined by the volume type. Persistent volumes (PVs) are specific to a cluster, are generally provisioned by an administrator, and tie into an existing storage resource. PVs can therefore outlast a specific pod.
Kubernetes relies on container images that it stores in a container registry. It can be a third party registry or one an organization configures.
Namespaces are virtual clusters inside a physical cluster. They are intended to provide virtually separated work environments for multiple users, teams, and prevent teams from hindering each other by limiting what Kubernetes objects they can access.
At the pod level, Kubernetes containers within a pod can reach other ports via localhost and share their IP addresses and network namespaces.
Kubernetes Architecture Best Practices
Kubernetes architecture is premised on availability, scalability, portability, and security. Its design is intended to distribute workloads across available resources more efficiently, optimizing the cost of infrastructure.
High Availability
Most container orchestration engines deliver application availability, but Kubernetes high availability architecture is designed to achieve availability of both applications and infrastructure.
Kubernetes architecture ensures high availability on the application front using replication controllers, replica sets, and pet sets. Users can set the minimum number of running pods at any time. The declarative policy can return the deployment to the desired configuration if a pod or container crashes. Configure stateful workloads for high availability using pet sets.
Kubernetes HA architecture also supports infrastructure availability with a wide range of storage backends, from block storage devices such as Google Compute Engine persistent disk and Amazon Elastic Block Store (EBS), to distributed file systems such as GlusterFS and network file system (NFS), and specialized container storage plugins such as Flocker.
Moreover, each Kubernetes cluster component can be configured for high availability. Health checks and load balancers can further ensure availability for containerized applications.
Scalability
Applications deployed in Kubernetes are microservices, composed of many containers grouped into series as pods. Each container is logically designed to perform a single task.
Kubernetes 1.4 supports cluster auto-scaling, and Kubernetes on Google Cloud also supports auto-scaling. During auto-scaling, Kubernetes and the underlying infrastructure coordinate to add additional nodes to the cluster when no available nodes remain to scale pods across.
Portability
Kubernetes is designed to offer choice in cloud platforms, container runtimes, operating systems, processor architectures, and PaaS. For example, you can configure a Kubernetes cluster on various Linux distributions, including CoreOS, Red Hat Linux, CentOS, Fedora, Debian, and Ubuntu. It can be deployed to run locally, in a bare metal environment; and in virtualization environments based on vSphere, KVM, and libvirt. Serverless architecture for Kubernetes can run on cloud platforms such as Azure, AWS, and Google Cloud. It’s also possible to create hybrid cloud capabilities by mixing and matching clusters on-premises and across cloud providers.
Security
Kubernetes application architecture is configured securely at multiple levels. For a detailed look at Kubernetes Security, please see our discussion here.
Configuring Kubernetes Architecture Security
To secure Kubernetes clusters, nodes, and containers, there are several best practices based on DevOps practices and cloud-native principles to follow:
Update Kubernetes to the latest version. Only the latest three versions of Kubernetes are supported with security patches for newly identified vulnerabilities.
Configure the Kubernetes API server securely. Deactivate anonymous/unauthenticated access and use TLS encryption for connections between the API server and kubelets.
Secure etcd. etcd itself is a trusted source, but serves client connections only over TLS.
Secure the kubelet. Deactivate anonymous access to the kubelet. Start the kubelet with the –anonymous-auth=false flag and limit what the kubelet can access with the NodeRestriction admission controller.
Embed security early in the container lifecycle. Ensure shared goals between DevOps and security teams.
Reduce operational risk using Kubernetes-native security controls. When possible, leverage native Kubernetes controls to enforce security policies so your own security controls and the orchestrator don’t collide.
Does VMware NSX Advanced Load Balancer Offer Services for Kubernetes Container Architecture?
A modern, distributed application services platform is the only option for delivering an ingress gateway for applications based on Kubernetes microservices architecture. For web-scale, cloud-native applications deployed using container technology as microservices, traditional appliance-based ADC solutions are not up to the task of managing Kubernetes container clusters. Each can have hundreds of pods with thousands of containers, mandating policy driven deployments, full automation, and elastic container services.
The VMware NSX Advanced Load Balancer’s Kubernetes ingress services provide enterprise-grade application services including ingress controller, LB, WAF, and GSLB for distributed apps (both traditional & cloud-native) beyond containers to VMs and bare metal. The VMware NSX Advanced Load Balancer helps simplify operations for production ready clusters across multi-cloud, multi-region, and multi-infra environments. Learn how to deploy and automate here.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.