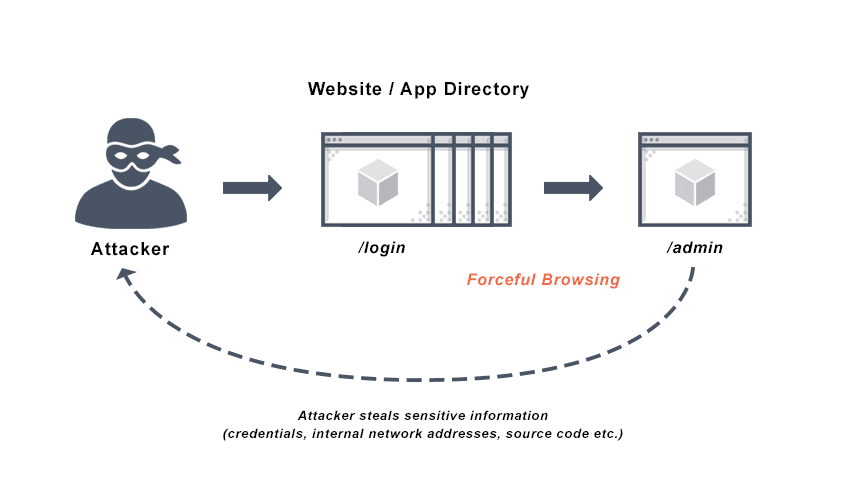
Forceful Browsing Definition
Forceful browsing, also called forced browsing, is a brute force attack that aims to enumerate files and gain access to resources that the application does not reference, but can still retrieve.
Using brute force techniques, an attacker can search the domain directory for unlinked contents such as temporary directories and files, old configuration files, and old backup data. These resources are valuable to intruders because they may store sensitive information about web applications and operational systems, such as credentials, internal network addresses, and source code.
Forced browsing attacks can be performed manually when application index pages and directories are based on predictable values or number generation. For more common directory names and files, this type of attack can also be conducted using automated tools.
The forced browsing attack is also known as active directory enumeration, file access enumeration, predictable resource location, authentication forceful browsing, and resource enumeration.
What is Forceful Browsing?
Forced browsing is an attack that allows intruders access to restricted pages and web server resources outside of the correct sequence. Authentication protects most web applications so only users with sufficient rights can access specific areas and pages after providing their username and password. Forced browsing attempts to bypass these controls by directly requesting access to areas beyond their access level or to authenticated areas of the application without providing valid credentials. Improper configuration of permissions on these pages leaves them vulnerable to unauthorized users and forceful browsing attacks.
Forced browsing often succeeds when attackers know, infer, or guess the target URL directly. This type of brute force attack allows an unauthorized user to view directory names and files not intended for viewing by the public, and uncover hidden website functionality and content. To prevent forced browsing, it is critical to restrict users’ access rights to all pages in the web application interface, not just those available to the user, to the correct privilege level.
These hidden files are rich resources to forceful browsing intruders, because they may contain administrative site sections, backup files, configuration files, demo applications, logs, sample files, and temporary files. These files may include database information, file paths to other sensitive areas, machine names, passwords, sensitive information about the website, and web application internals, among other sensitive data.
The attacker can make brute force attacks based on educated guesses because files and paths frequently reside in standard locations and are named based on common conventions. If the site owner fails to enforce restricted files, scripts, or URLs that reside in the web server directory with appropriate sequencing logic or authorization logic, they may be vulnerable to forceful browsing.
Forceful Browsing Methods
Forceful browsing can be either manual or automated. An attacker can manually predict unlinked resources using number rotation techniques or simply with good guesses when URLs are generated in a predictable way. Hackers can also use automated tools for common files and directory names. Most open-source and commercial scanners typically also search for indirectly linked yet valuable, predictable resources that contain sensitive information.
Forced Browsing Attacks
Here are several forced browsing attack examples:
Example 1
In this example, we see an attacker manually orient and identify resources by modifying URL parameters. The user, user504, checks their calendar using the following URL:
http://www.vulnerablesite.com/users/calendar.php/user504/20200615
This URL identifies both the date and the user name, allowing attackers to make forced browsing attacks by predicting the dates and user names of other users:
http://www.vulnerablesite.com/users/calendar.php/user602/20200618
This attack is successful if the unauthorized user can access the other user’s agenda. Part of the reason this kind of forced browsing attack succeeds is a poor implementation of the authorization mechanism.
Example 2
Similarly, websites that fail to enforce proper checks before processing operations may be vulnerable to forced browsing attacks.
In this example, a hacker accesses a money transfer URL from a bank directly, without following the web application workflow, by analyzing HTTP requests for the online money transfer:
http://www.vulnerablebank.com/transfer-money.asp?From_account=12345678&To_account=87654321&amount=100
Now this attacker can try their own account number in the To_account number value. A successful attack of this kind will appear to have the From_account owner’s permission.
The flaw here is the web application fails to verify the login—the successful performance of the first step—before performing the money transfer, the second step. This is the forced browsing vulnerability.
Example 3
In this example, Alice creates a grocery delivery app called “Food Drop” which allows users to order food from people doing shopping for themselves in their area. One of the features shows users how much time and how many miles they have saved using the app, and this includes the ability to see the routes their deliveries have taken.
Bob, a hacker, downloads and installs “Food Drop.” He creates an account and logs in. First, Bob learns how the backend server and the application communicate using basic network-sniffing techniques. Then, he watches network traffic using a network proxy on his device so he can better understand “Food Drop” and its functionality.
The network sniffer output tells Bob that a simple HTTP GET request fetches user history, and that there is a number in the path of the GET request: 333. There are no authentication headers in the request.
An attacker like Bob can use an API tester tool to generate a customized HTTP GET request with different numbers, and eventually one will work, allowing him to access the history:
/vulnerable_api/mobile/history/333
/vulnerable_api/mobile/history/147
Bob may also enumerate files on the application web server to access files and user data.
Security Misconfiguration Attacks
Forced browsing attacks are the result of a type of security misconfiguration vulnerability. These kinds of vulnerabilities occur when insecure configuration or misconfiguration leave web application components open to attack.
Misconfiguration vulnerabilities may exist in subsystems or software components. Some examples of this include remote administration functionality and other unneeded services that software may have enabled, or sample configuration files or scripts, or even default user accounts that web server software may arrive with. These existing features leave access to the system an attacker can exploit.
The following types of attacks, along with brute force and forceful browsing, can target misconfiguration vulnerabilities:
- Buffer overflow
- Code injection
- Command injection
- Credential stuffing
- Cross-site scripting (XSS)
How to Prevent Forced Browsing
There are two techniques that protect against forced browsing: using proper access control and enforcing an application URL space allowlist.
Using proper access control and authorization policies means giving users access commensurate with their privileges, and no more. A web application firewall (WAF) offers access control enforcement by implementing authorization policies along with protection against session-based attacks at the URL level.
Creating an allowlist, involves granting explicit access to safe, allowed URLs. These URLs that are considered a necessary part of the functional application, essentially, and any request outside this URL space will be denied by default.
It is time-consuming and tedious to create and maintain such an allowlist manually. A WAF can automatically create and enforce your allowlist, analyzing trusted traffic to learn the valid URL space. It can also enforce a block list of directories and files that are often left vulnerable.
Even more advanced WAF architectures may contain security flaws that render them vulnerable to forced browsing attacks. However, approaches to configuring WAF security architecture exist that optimize the effectiveness of the WAF and minimize the frequency and success of common attacks.
Basic secure single-tier or two-tier web application architectures—in which the same host machine is home to the application’s database server and web server—is useful for early stages of project development. However, it introduces a single point of failure, so it is less ideal for production applications. Instead, a multi-tier / N-tier architecture avoids a single point of failure and provides compartmentalization by separating different components of the application according to their functions into multiple tiers, each running on a different system.
In most application architectures, position the WAF behind the load balancing tier to maximize performance, utilization, visibility, and reliability. And while WAFs can be deployed anywhere in the data path, they are ideally positioned closest to the application they are protecting behind the load balancing tier for those same performance related reasons.
Does VMware NSX Advanced Load Balancer Prevent Forceful Browsing?
The VMware NSX Advanced Load Balancer platform provides web application security for online services from a wide range of malicious security attacks, including forceful browsing, cross-site scripting (XSS), and SQL injection. VMware NSX Advanced Load Balancer’s WAF security detects and filters out threats which could degrade, compromise, or expose online applications to denial-of-serivce (DoS) attacks. WAF security examines HTTP traffic before it reaches the application server. It also protects against unauthorized transfer of data from the server, providing an effective forceful browsing solution.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.