Fault Tolerance Definition
Fault Tolerance simply means a system’s ability to continue operating uninterrupted despite the failure of one or more of its components. This is true whether it is a computer system, a cloud cluster, a network, or something else. In other words, fault tolerance refers to how an operating system (OS) responds to and allows for software or hardware malfunctions and failures.
An OS’s ability to recover and tolerate faults without failing can be handled by hardware, software, or a combined solution leveraging load balancers(see more below). Some computer systems use multiple duplicate fault tolerant systems to handle faults gracefully. This is called a fault tolerant network.
What is Fault Tolerance?
The goal of fault tolerant computer systems is to ensure business continuity and high availability by preventing disruptions arising from a single point of failure. Fault tolerance solutions therefore tend to focus most on mission-critical applications or systems.
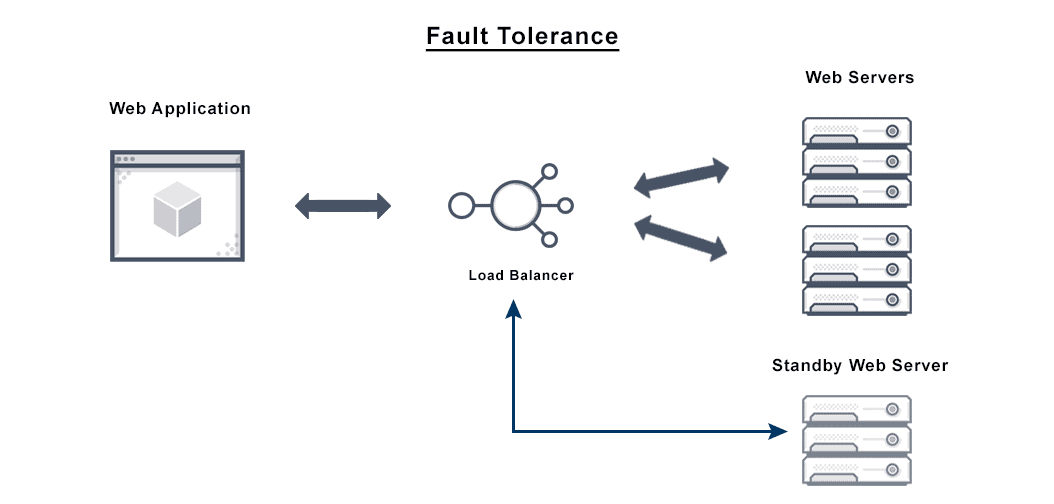
Fault tolerant computing may include several levels of tolerance:
- At the lowest level, the ability to respond to a power failure, for example.
- A step up: during a system failure, the ability to use a backup system immediately.
- Enhanced fault tolerance: a disk fails, and mirrored disks take over for it immediately. This provides functionality despite partial system failure, or graceful degradation, rather than an immediate breakdown and loss of function.
- High level fault tolerant computing: multiple processors collaborate to scan data and output to detect errors, and then immediately correct them.
Fault tolerance software may be part of the OS interface, allowing the programmer to check critical data at specific points during a transaction.
Fault-tolerant systems ensure no break in service by using backup components that take the place of failed components automatically. These may include:
- Hardware systems with identical or equivalent backup operating systems. For example, a server with an identical fault tolerant server mirroring all operations in backup, running in parallel, is fault tolerant. By eliminating single points of failure, hardware fault tolerance in the form of redundancy can make any component or system far safer and more reliable.
- Software systems backed up by other instances of software. For example, if you replicate your customer database continuously, operations in the primary database can be automatically redirected to the second database if the first goes down.
- Redundant power sources can help avoid a system fault if alternative sources can take over automatically during power failures, ensuring no loss of service.
High Availability vs Fault Tolerance
Highly available systems are designed to minimize downtime to avoid loss of service. Expressed as a percentage of total running time in terms of a system’s uptime, 99.999 percent uptime is the ultimate goal of high availability.
Although both high availability and fault tolerance reference a system’s total uptime and functionality over time, there are important differences and both strategies are often necessary. For example, a totally mirrored system is fault-tolerant; if one mirror fails, the other kicks in and the system keeps working with no downtime at all. However, that’s an expensive and sometimes unwieldy solution.
On the other hand, a highly available system such as one served by a load balancer allows minimal downtime and related interruption in service without total redundancy when a failure occurs. A system with some critical parts mirrored and other, smaller components duplicated has a hybrid strategy.
In an organizational setting, there are several important concerns when creating high availability and fault tolerant systems:
Cost. Fault tolerant strategies can be expensive, because they demand the continuous maintenance and operation of redundant components. High availability is usually part of a larger system, one of the benefits of a load balancing solution, for example.
Downtime. The greatest difference between a fault-tolerant system and a highly available system is downtime, in that a highly available system has some minimal permitted level of service interruption. In contrast, a fault-tolerant system should work continuously with no downtime even when a component fails. Even a system with the five nines standard for high availability will experience approximately 5 minutes of downtime annually.
Scope. High availability systems tend to share resources designed to minimize downtime and co-manage failures. Fault tolerant systems require more, including software or hardware that can detect failures and change to redundant components instantly, and reliable power supply backups.
Certain systems may require a fault-tolerant design, which is why fault tolerance is important as a basic matter. On the other hand, high availability is enough for others. The right business continuity strategy may include both fault tolerance and high availability, intended to maintain critical functions throughout both minor failures and major disasters.
What are Fault Tolerance Requirements?
Depending on the fault tolerance issues that your organization copes with, there may be different fault tolerance requirements for your system. That is because fault-tolerant software and fault-tolerant hardware solutions both offer very high levels of availability, but in different ways.
Fault-tolerant servers use a minimal amount of system overhead to achieve high availability with an optimal level of performance. Fault-tolerant software may be able to run on servers you already have in place that meet industry standards.
What is Fault Tolerance Architecture?
There is more than one way to create a fault-tolerant server platform and thus prevent data loss and eliminate unplanned downtime. Fault tolerance in computer architecture simply reflects the decisions administrators and engineers use to ensure a system persists even after a failure. This is why there are various types of fault tolerance tools to consider.
At the drive controller level, a redundant array of inexpensive disks (RAID) is a common fault tolerance strategy that can be implemented. Other facility level forms of fault tolerance exist, including cold, hot, warm, and mirror sites.
Fault tolerance computing also deals with outages and disasters. For this reason a fault tolerance strategy may include some uninterruptible power supply (UPS) such as a generator—some way to run independently from the grid should it fail.
Byzantine fault tolerance (BFT) is another issue for modern fault tolerant architecture. BFT systems are important to the aviation, blockchain, nuclear power, and space industries because these systems prevent downtime even if certain nodes in a system fail or are driven by malicious actors.
What is the Relationship Between Security and Fault Tolerance?
Fault tolerant design prevents security breaches by keeping your systems online and by ensuring they are well-designed. A naively-designed system can be taken offline easily by an attack, causing your organization to lose data, business, and trust. Each firewall, for example, that is not fault tolerant is a security risk for your site and organization.
What is Fault Tolerance in Cloud Computing?
Conceptually, fault tolerance in cloud computing is mostly the same as it is in hosted environments. Cloud fault tolerance simply means your infrastructure is capable of supporting uninterrupted functionality of your applications despite failures of components.
In a cloud computing setting that may be due to autoscaling across geographic zones or in the same data centers. There is likely more than one way to achieve fault tolerant applications in the cloud in most cases. The overall system will still demand monitoring of available resources and potential failures, as with any fault tolerance in distributed systems.
What Are the Characteristics of a Fault Tolerant Data Center?
To be called a fault tolerant data center, a facility must avoid any single point of failure. Therefore, it should have two parallel systems for power and cooling. However, total duplication is costly, gains are not always worth that cost, and infrastructure is not the only answer. Therefore, many data centers practice fault avoidance strategies as a mid-level measure.
Load Balancing Fault Tolerance Issues
Load balancing and failover solutions can work together in the application delivery context. These strategies provide quicker recovery from disasters through redundancy, ensuring availability, which is why load balancing is part of many fault tolerant systems.
Load balancing solutions remove single points of failure, enabling applications to run on multiple network nodes. Most load balancers also make various computing resources more resilient to slowdowns and other disruptions by optimizing distribution of workloads across the system components. Load balancing also helps deal with partial network failures, shifting workloads when individual components experience problems.
Does VMware NSX Advanced Load Balancer Offer a Fault Tolerance Solution?
The VMware NSX Advanced Load Balancer offers load balancing capabilities that can keep your systems online reliably. The VMware NSX Advanced Load Balancer aids fault tolerance by automatically instantiating virtual services when one fails, redistributing traffic, and handling workload moves or additions, reducing the chance of a single point of failure strangling your system.
For more on the actual implementation of load balancers, check out our Application Delivery How-To Videos.
The VMware NSX Advanced Load Balancer Software Load Balancer