Web Scraping Definition
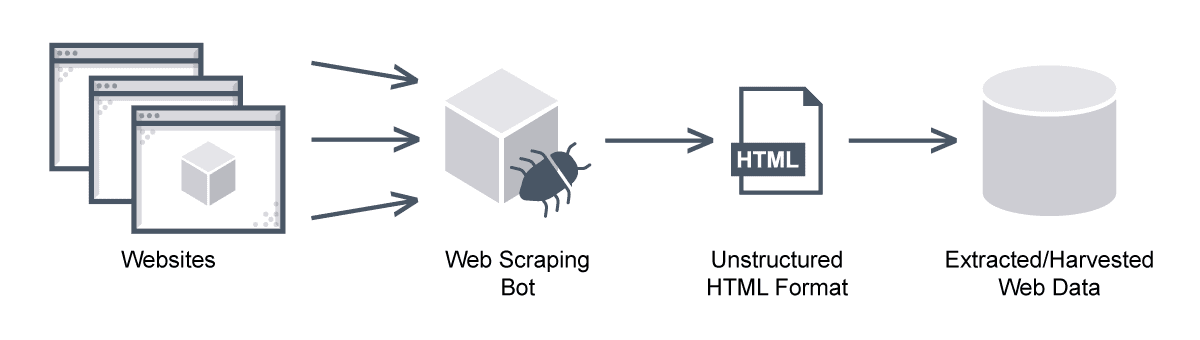
Web scraping is the process of pulling data from a website using bots. Unlike screen scraping, which merely copies the onscreen image displayed by pixels, web scraping removes content and extracts its underlying HTML code and its stored data so whoever has it can replicate the content of the whole website.
Web Scraping FAQs
What is Web Scraping?
Web scraping is a technique for extracting massive amounts of data from websites automatically—mostly in an unstructured, HTML format. Web scraping is also called web data extraction or web harvesting.
Although web scraping and screen scraping are sometimes referred to as if they are the same, they each extract different kinds of data, with only web scraping collecting data past the screen level.
There are also online web scraping services, and custom code for manual web scraping from scratch. Many larger sites such as Google allow access to their data in a structured format through web scraping APIs.
Web scraping is a kind of data mining. Users of web scraping software are often hoping to harness data for their own purposes, but they may also aim to sell data or use it for promotional purposes. Items such as auction prices and details, weather reports, product listings and descriptions, or other data are commonly sought.
Because some websites do not allow this kind of data mining or web scraping, the practice is controversial. However, web scraping remains an important way of using aggregated data resources.
How Does Web Scraping Work?
There are two pieces to web scraping: the crawler and the scraper. The crawler, an artificial intelligence algorithm, follows internet links to browse the web for specific data. The scraper extracts data from the website and its actual design affects how accurately and quickly it works. Obviously, if the scraper is more specific in the data it targets, it is also faster.
As an example, you might want to scrape a consumer sales web page for the kinds of smartphones available. You certainly want the model numbers, but you probably don’t need customer reviews; limiting the scrape improves the speed.
This knowledge also helps detect and stop web scraping. Understanding the specific kinds of data scrapers are targeting on a site and how they are likely to target it helps to protect it.
There are several types of web scraping:
- Self-built or manual web scrapers. These demand sophisticated programming skills, but can also achieve many different goals and may be difficult to detect.
- Browser extensions. These are simply added to and integrated with a web browser, so they are limited by the browser itself.
- Cloud web scraping. These web scrapers run on an off-site server in the cloud, independent of local resources.
- Real-time or dynamic web scraping. This is the process of scraping data from sites as they change in real-time.
Any of these can be deployed against any site.
Why is Python a popular programming language for web scraping?
Python with or without regular expressions (RegEx) is among the most popular web scraping languages. Python has a variety of libraries that were created specifically for web scraping and it easily handles most of the processes.
In addition, Beautiful soup is a Python library that is designed for web scraping, and Scrapy is a popular open-source web scraping framework. Both are ideal for data extraction from HTML documents via API web scraping.
What Are the Advantages of Web Scraping?
What is web scraping used for? Web scraping has advantages in various applications across many industries, and it has legitimate and illegal uses.
The benefits of web scraping include some of its legitimate uses:
- Crawling sites with search engine bots to analyze, index, and rank its content
- News and financial sites use web scraping for news monitoring
- Price comparison sites auto-fetch product descriptions and prices for allied seller websites with bots
- Market research professionals collect social media posts and other scraped data from forums for sentiment analysis
- Real estate bots extract listings from site to site
- Email marketing businesses can also use web scraping to build contact information.
However, web scraping is also used for malicious purposes, including theft of intellectual property and undercutting prices. A baseline for malicious net web scraping is permission: when data is extracted without permission of its owners, such as in the case of content theft, IP theft, or price scraping, this is malicious. Here are some examples:
Price scraping. This kind of web scraping allows perpetrators to target websites of competitors. They can scrape prices in real-time to continuously undercut the competition and mimic their strategies.
Content scraping. Large-scale content theft is common, especially targeting news sites and online product catalogs. For organizations that rely on generating fresh content, enterprise web scraping can be a serious problem.
Phishing and other attacks. Web scraping leaves sites and businesses vulnerable to spear phishing, social engineering, and other attacks, and otherwise leak sensitive scraped data. It can allow hackers to learn details like supervisor names, titles of ongoing projects, and the identities of trusted partners, vendors, and organizations.
Web Scraping vs Web Crawling
What is the difference between web scraping and web crawling? In brief, while web crawling is about discovering or finding URLs on the web, web scraping focuses on data extraction from one or more websites. The web scraping process typically combines web crawling and scraping.
And what is the difference between data scraping vs web scraping? Data scraping merely refers to detecting and extracting data, so essentially this is two ways of saying the same thing.
Data Mining vs Web Scraping?
Data mining, however, is slightly different from either data scraping or web scraping.
While web scraping involves gathering and structuring data from websites in a usable format, it does not involve data review or processing. In contrast, data mining refers to the analysis of large data sets to identify useful patterns and other information. Data mining does not require data extraction or processing.
How to Detect Web Scraping
Web scraping tools are bots or other software programmed to extract information from databases. Many are entirely customizable: to identify unique HTML structures, extract data from APIs, extract content and transform it, and store scraped data.
However, it can be difficult to distinguish between legitimate and malicious bots because they all share the same basic feature: web scraping automation to more easily access website data.
However, there are two important differences:
- Legitimate bots identify with the organization they scrape rather than impersonating legitimate traffic. For example, malicious bots may create false HTTP user agents.
- Legitimate bots follow the rules set by a site’s robot.txt file, while malicious scrapers crawl anywhere on the website.
Users require substantial resources to run web scraper bots. Legitimate operators invest heavily in servers that can process the data they extract. Malicious operators might instead rely on specialized, distributed web scraping architecture—computers infected with the same malware that are geographically dispersed but controlled from a central location.
This allows a single perpetrator with a lower budget to run a botnet with the combined power of infected systems. It also provides a pattern for sophisticated web scraping protection tools to look for.
Advanced Web Scraping Solutions and Web Scraping Tools
Malicious web scraping software and scraper bots are becoming more advanced. This renders many common security measures ineffective. Real-time, granular traffic analysis helps ensure that both human and bot traffic to a website is legitimate. This might include the close inspection of HTML headers and header signatures, IP reputation analysis, behavior analysis including tracking illogical browsing patterns and the rate of http requests, and the use of progressive challenges.
Legitimate web scraping techniques support threat intelligence and enable security teams to meet these challenges. These kinds of web scraping companies target sites including darknet sites and forums to scrape for cyber threat intelligence.
Does Avi Protect Against Web Scraping?
Even if your competitors or attackers automate web scraping, Avi offers customized protection, and visibility into attacks to prevent ongoing attacks. By delivering software load balancers, container ingress, and web application firewall services, Avi also keeps applications available, secure, and responsive. Avi also provides scaling capacity, natively mitigating against dozens of DDoS attacks.
Learn more about how Avi protects against web scraping here.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.