High Availability Definition
High Availability (HA) describes systems that are dependable enough to operate continuously without failing. They are well-tested and sometimes equipped with redundant components.
“Availability” includes two periods of time: how much time a service is accessible, and how much time the system needs to respond to user requests. High availability refers to those systems that offer a high level of operational performance and quality over a relevant time period.
What is High Availability?
When it comes to measuring availability, several factors are salient. These include recovery time, and both scheduled and unscheduled maintenance periods.
Typically, availability as a whole is expressed as a percentage of uptime defined by service level agreements (SLAs). A score of 100 percent characterizes a system that never fails.
What Are High Availability Clusters?
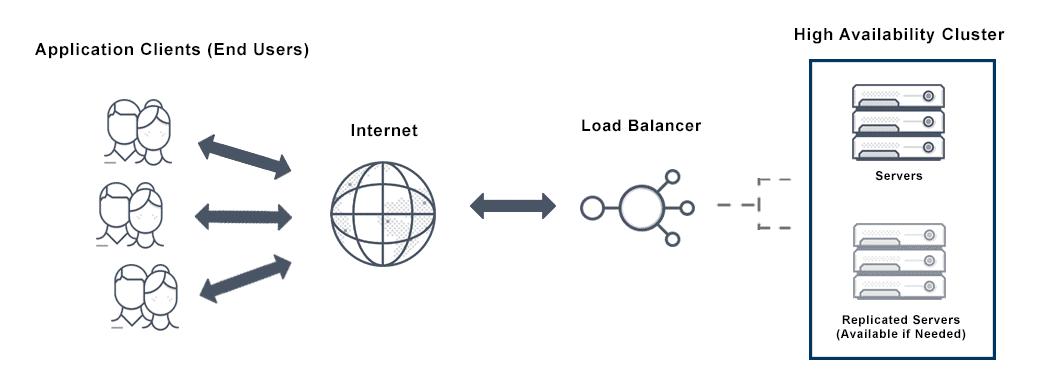
High-availability clusters are computers that support critical applications. Specifically, these clusters reliably work together to minimize system downtime.
In terms of failover cluster vs high availability preference, a failover cluster, which is a redundant system triggered when the main system encounters performance issues, is really just a strategy to achieve high availability.
Why is High Availability Important?
To reduce interruptions and downtime, it is essential to be ready for unexpected events that can bring down servers. At times, emergencies will bring down even the most robust, reliable software and systems. Highly available systems minimize the impact of these events, and can often recover automatically from component or even server failures.
High Availability Architecture
Of course, it is critical for systems to be able to handle increased loads and high levels of traffic. But identifying possible failure points and reducing downtime is equally important. This is where a highly available load balancer comes in, for example; it is a scalable infrastructure design that scales as traffic demands increase. Typically this requires a software architecture, which overcomes hardware constraints..
In this process, users set up servers to switch responsibilities to a remote server as needed. They should also evaluate each piece of hardware for durability using vendor metrics such as mean time between failures (MTBF).
How High Availability Works
To achieve high availability, first identify and eliminate single points of failure in the operating system’s infrastructure. Any point that would trigger a mission critical service interruption if it was unavailable qualifies here.
There may be singular components in your infrastructure that are not single points of failure. One important question is whether you have mechanisms in place to detect any data loss or other system failures and adapt quickly. Another is whether you have redundant system components in place that can cover the same tasks.
Which High Availability Products Do You Need?
In practice, high availability products are the first line of defense, although it takes more to achieve this level of durable performance. Important factors include: data quality, environmental conditions, hardware resilience, and strategically durable networks and software.
There are many ways to lose data, or to find it corrupted or inconsistent. Any system that is highly available protects data quality across the board, including during failure events of all kinds.
Highly available hardware includes servers and components such as network interfaces and hard disks that resist and recover well from hardware failures and power outages.
Another part of an HA system is a high availability firewall. These are typically multiple web application firewalls placed strategically throughout networks and systems to help eliminate any single point of failure and enable ongoing failover processing.
Networks and software stacks also need to be designed to resist and recover from failures—because they will happen, even in the best of circumstances.
What is the Difference Between High Availability and Redundancy?
Redundancy alone cannot ensure high availability. A system also needs failure detectability mechanisms.
The ability to conduct high availability testing and the capacity to take corrective action each time one of the stack’s components becomes unavailable are also essential.
Top-to-bottom or distributed approaches to high availability can both succeed, and hardware or software based techniques to reduce downtime are also effective.
Redundancy is a hardware based approach. On the other hand, implementing high availability strategies nearly always involves software.
High Availability vs Fault Tolerance
High availability and fault tolerance both refer to techniques for delivering high levels of uptime. However, fault tolerant vs high availability strategies achieve that goal differently.
Fault tolerant computing demands complete redundancy in hardware. Multiple systems operate in tandem to achieve fault tolerance, identically mirroring applications and executing instructions together. When the main system fails, another system should take over with no loss in uptime.
To achieve fault tolerant computing, you need specialized hardware. It must be able to immediately detect faults in components and enable the multiple systems to run in tandem.
This kind of system retains the memory and data of its programs, which is a major benefit. However, it may take longer to adapt to failures for networks and systems that are more complex. In addition, software problems that cause systems to crash can sometimes cause redundant systems operating in tandem to fail similarly, causing a system-wide crash.
In contrast, a high availability solution takes a software- rather than a hardware-based, approach to reducing server downtime. Instead of using physical hardware to achieve total redundancy, a high availability cluster locates a set of servers together.
These high availability servers both possess failover capabilities and monitor each other. If the primary server has issues, only one of the backup servers needs to detect them. It can then restart the problem application that tripped up the crashed server.
High availability systems recover speedily, but they also open up risk in the time it takes for the system to reboot. Fault tolerant systems protect your business against failing equipment, but they are very expensive and do not guard against software failure.
This means that in most verticals, especially software-driven services, a high availability architecture makes a lot of sense. It is highly cost-effective compared to a fault tolerant solution, which cannot handle software issues in the same way.
High Availability vs Disaster Recovery
Similarly, it is important to mention the difference between high availability and disaster recovery here. Disaster recovery (DR), just like it sounds, is a comprehensive plan for recovery of critical operations and systems after catastrophic events.
However, if you have deployed a highly available and fault tolerant system, for example, why engage in this kind of planning?
DR is typically focused on getting back online and running after a catastrophic event. High availability is focused on serious but more typical failures, such as a failing component or server. A disaster recovery plan may cope with the loss of an entire region, for example, although both are related.
What is a Highly Available Load Balancer?
Typically, availability as a whole is expressed as a percentage of uptime. A highly available load balancer can achieve optimal operational performance through either a single-node deployment or through a deployment across a cluster. In a single-node deployment, a single load-balancing controller performs all administrative functions, as well as all analytics data gathering and processing. In a high availability load balancing cluster, additional nodes provide node-level redundancy for the load-balancing controller and maximize performance for CPU-intensive analytics functions.
Does The VMware NSX Advanced Load Balancer Offer Solutions for High Availability in Load Balancing?
The VMware NSX Advanced Load Balancer offers a solution which can be configured for high availability load balancing in a number of different modes. Controller High Availability provides node-level redundancy for Controllers. A single Controller is deployed as the leader node, then two additional Controllers are added as follower nodes. Service Engine High Availability provides service-engine-level redundancy within a service engine group. If a service engine within the group fails, high availability heals the failure and compensates for the reduced site capacity. Read more about VMware NSX Advanced Load Balancer’s Solutions for high availability in load balancing here: Overview of VMware NSX Advanced Load Balancer.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.